Why, how, and what you should do to turn ML from a buzzword to reality for your production line
For many years, my days at work looked very different than how they do today. That is not too surprising, considering I moved from designing and manufacturing Semiconductors & Opto-Electronics products to running a SW startup. Actually, my challenges during those years had a lot to do with founding a start-up, Vanti.
So how did my days look like when I was in charge of delivering a complex system, growing in production volume, and adhering to strict quality requirements? More often than not, we were in the process of investigating a phenomenon or trying to find the root cause of a failure we’re experiencing. To be completely honest, I always felt we weren’t doing a good enough job. More specifically, I thought we were spending too much time & resources to get the answers we needed. Whether actual material used for experiments or a dedicated task force of professionals spending many hours in the lab. Looking back, the examples where we were most successful in solving issues quickly & efficiently were when we managed to leverage actionable insights from data generated from the manufacturing operations.
One memorable example I have is a recurring short-circuit issue we had in one of our optoelectronic components. It appeared sporadically, as if for no explainable reason or pattern whatsoever. We could not predict when it was going to happen and how to prevent it. The investigation took place for several days, during which we were brainstorming multiple times a day, running all sorts of tests — electrical, environmental, visual inspections, and others. Eventually, we discovered that one of the schemes used by the testing equipment to power up the component was in high likelihood to cause overheating and ultimately failure of the device. Once identified, the solution was relatively quick and straightforward; reconfiguration of the power signal solved it immediately.
But this is just one of the many issues happening in modern manufacturing environments every single day. The main reason is that products are becoming more complex and the techniques used to manufacture them. The assembly and test procedures used in the manufacturing process are tightly coupled with the end products’ quality and functionality. It is especially true for high-end electronics products, spanning the communications, automotive, and consumer industries.
To ensure maximum productivity alongside the highest quality, production teams continuously work to control their processes better. The goal is always to be able to predict and prevent faults as early as possible in the process. Testing schemes and control limits are defined by the quality and process experts to do just that.
However, even in the best performing manufacturing environments, there is still hidden value to be unlocked. For example, it could be a systematic failure mechanism: “when placement position is X, and tests #4, #8 are 10% lower than average, the failure probability is 30% higher”. This is an insight that a simple control window/rule would not be able to detect. Another example could be a real-time detection of an anomalous component requiring a different set of process parameters (say, a soldering temperature) to function correctly.

So how can we ensure that we’re keeping an optimized production environment in a scalable way? Adding more resources (equipment and/or personnel) is costly and, in many cases, not even possible, as manufacturing experts are tough to find.
These scenarios make a perfect fit for ML and AI technologies. By combining advanced learning algorithms with the data generated by the production operation at every step, we can learn the genealogy of products as they are tied to their manufacturing process.
With such intimate knowledge of the product’s behavior, we can now detect those anomalies even before they occur within the production line or, even worse, after shipment to the end customer.
While detecting the anomalies holds significant value to manufacturers, the real major promise is knowing “why” and “what” — what created an anomaly and what needs to be done to correct it and prevent it from happening in the future. A combination of domain knowledge and an explainable approach to building the ML model is required to do that, but that’s a topic for our next discussion (stay tuned!).
This capability is just a first step to unlock tremendous value from data in the manufacturing space. The next steps will enable the translation of the knowledge to instruct machines in real-time, perform automated RCA (root cause analysis), predict and optimize multi-line variations or field-service, and much more.
How can one start benefiting from using AI/ML techniques in practice? Although it may sound quite intimidating, it can be straightforward.

Let’s start with the obvious; ML requires data. But what exactly does that mean?
At Vanti, we defined a reasonably simple framework and prerequisites for the dataset to see ML’s value by working with many customers.
Data requirements are divided into (how not) three parts:
- Type of data - we’re talking about two kinds of data. Product-related and process-related. The product-related data includes all tests and inspection results at every step of the manufacturing process, as documented for every single unit or batch. It is usually tabular data, which may consist of text and numerical values, continuous or discrete. The process-related data includes the process parameters/recipes configured and controlled by the machines or sensors embedded in them. Here, we will usually see time-series data, a standard output of modern manufacturing equipment today.
- Traceability — this is probably the essential part of the puzzle. We should identify the relevant data point acquired for every single unit/batch/module / etc. Learning the behavior of a product will not be possible if we can’t relate parameters to outcomes. The same applies to the process-related data. The timestamp should be reliable and consistent between different stations along with the production flow. The good news is that traceability is usually available through the S/N (batch number) or other identifiers. In some cases, a product tree is required to identify each data point’s source, but defining these relationships is a one-time effort in the onboarding process.
- Amount of data — that’s a question that comes up very often, and there are several aspects that have an impact on the answer: the ratio of pass/fail units in the dataset, “richness” of the dataset — meaning, do the key contributors are represented well enough in the data, availability of labels (does it contain a reliable indication of known failures) and more. That being said, a good starting point for required examples to build a good model is ten (10) examples for every parameter (rows ~= 10 x columns). That’s a considerably low number compared to traditional ML techniques, but using our proprietary architecture for model building, we’ve seen this work many times.
Once data is identified and extracted, the art of building a model starts. As mentioned above, learning the product and process genealogy in order to detect anomalies is at the heart of most manufacturing use-cases. For a more in-depth review of our approach to tackling this at Vanti, have a look at our recent blog post: how to detect unknown anomalies in manufacturing.
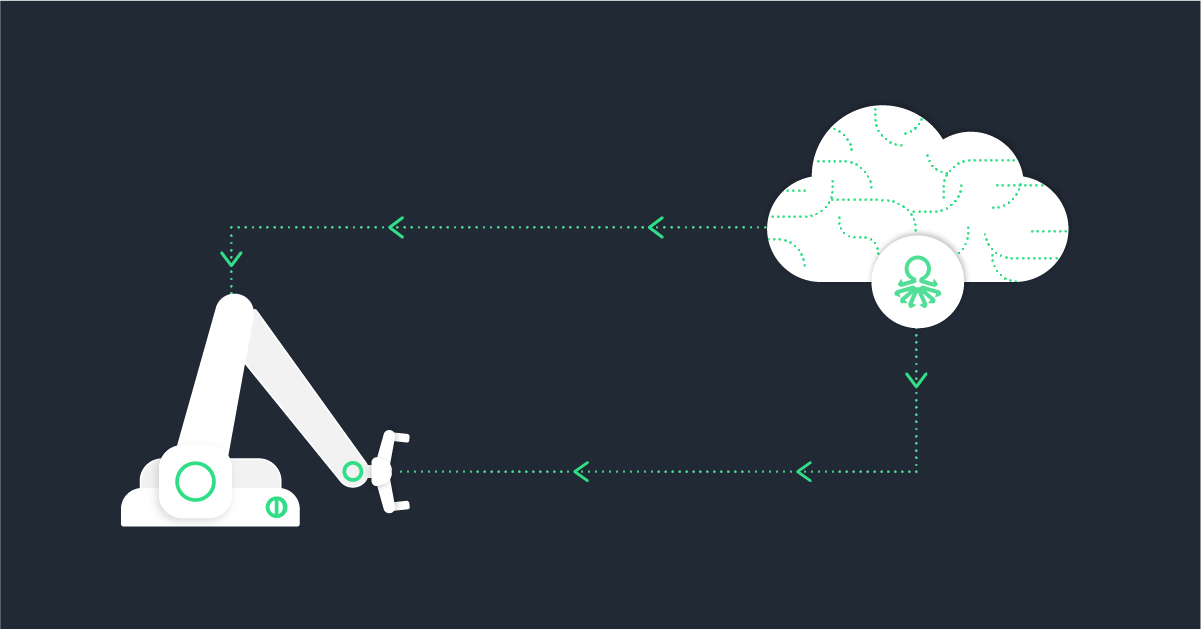
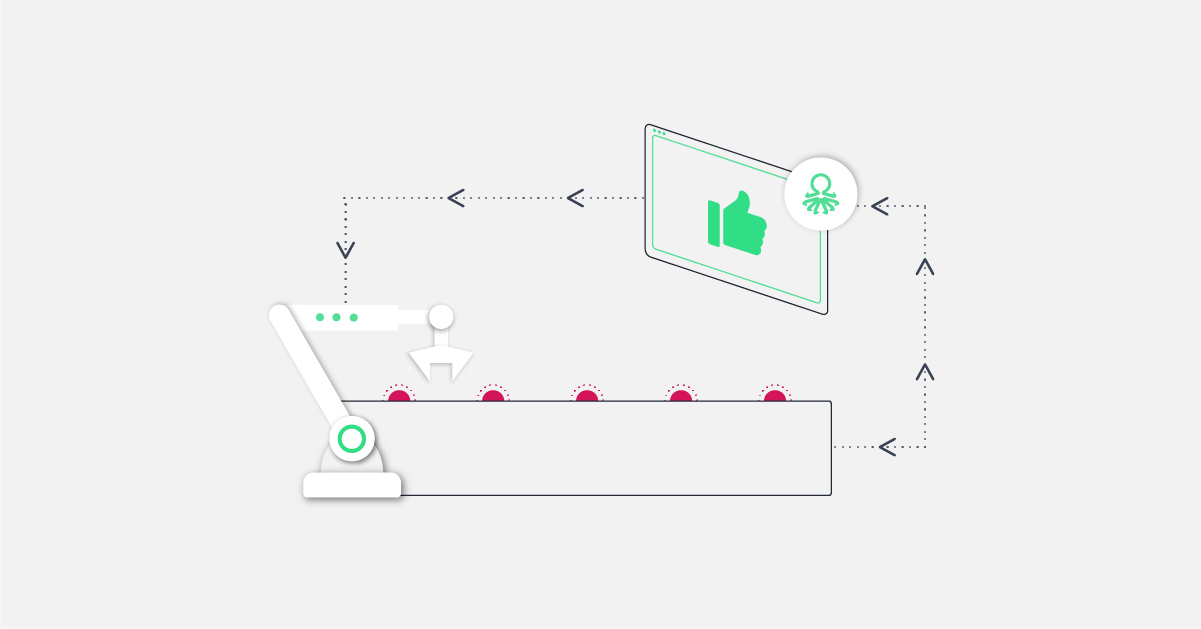
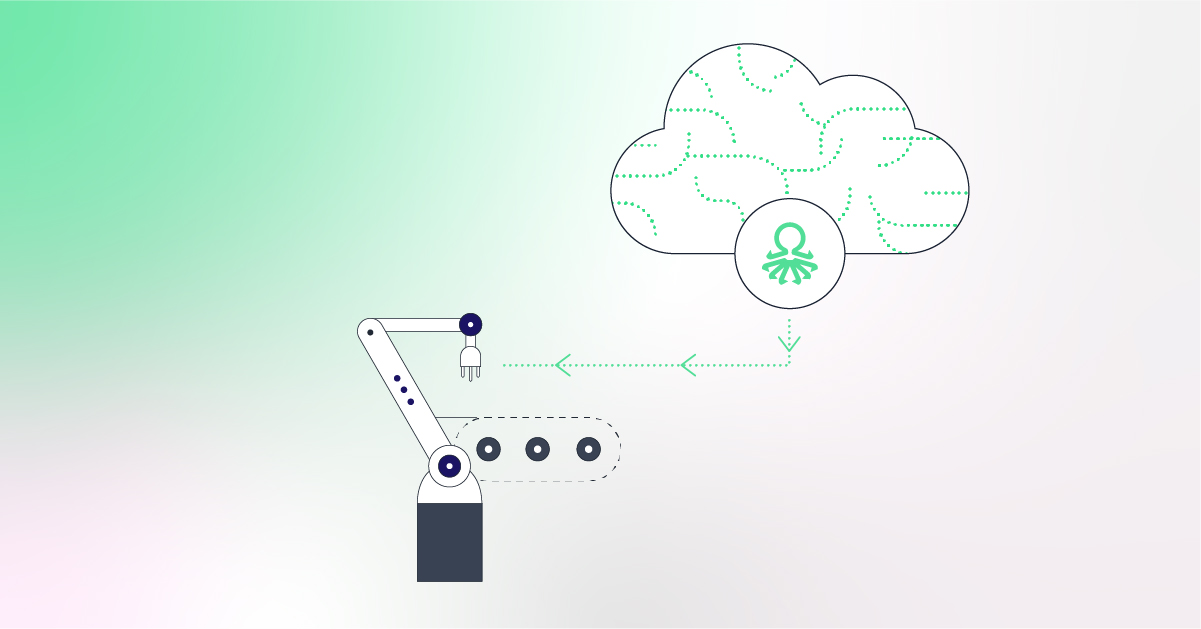
Ok, we built a model, now what? To use this model in your production line, meaning getting predictions about potentially faulty units or processes in real-time, we need a way to send collected data to the model and feed the result back to the line.
A simple, proven way to do just that is to set up a 2-way communication with the shop floor’s database through an API. Through a standard protocol, results are sent to the model. Predictions are then pushed to any application chosen by the customer (directly to the test equipment, to the operator’s mobile phone, or as simple as an email notification). Predictions can be ‘pass’ / ‘fail’ / ‘suspicious’ in this or any other format for every single manufactured unit.
But as mentioned previously, this is just half of the picture. In addition to the predictions, the operations teams also need to receive actionable information. A possible insight could be: “the placement process requires tighter limits for the new batch of components.” Insights are also delivered quickly through the same interface to be addressed by the production teams.

It may sound complicated if you haven’t done this before, but we have found the process can be done in a matter of hours. Here at Vanti, we’re accustomed to supporting our customers and working with them to build the first model and demonstrate value within just days.
Drop us a note at info@vanti.ai to request the full guide (with actual data sample and interface documentation), or schedule a 15-mins call with one of our experts.