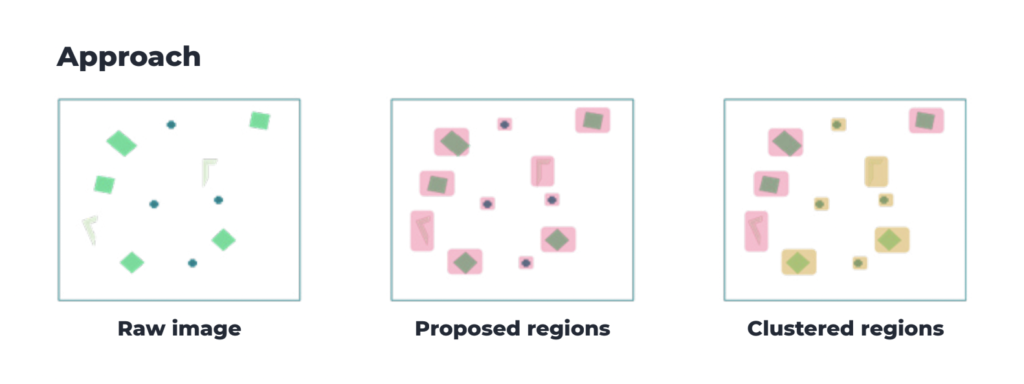
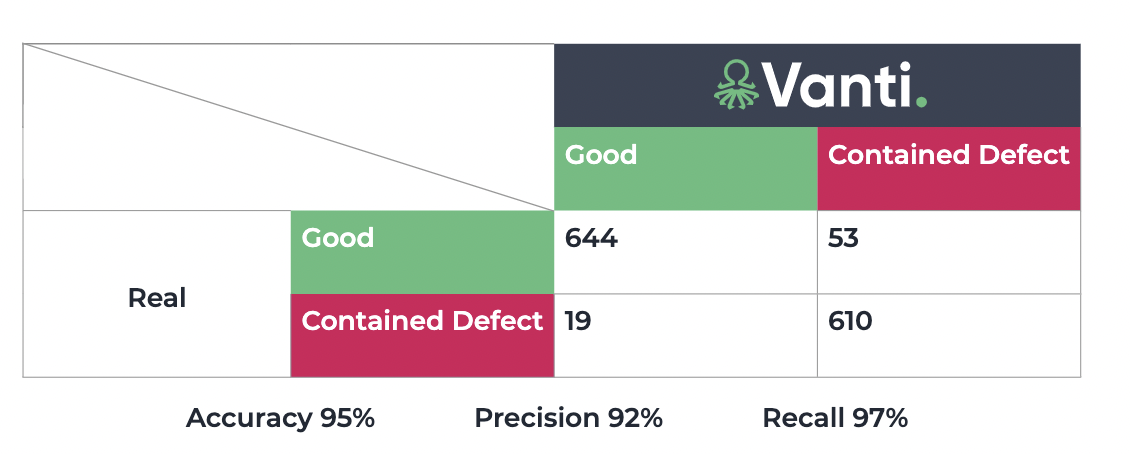
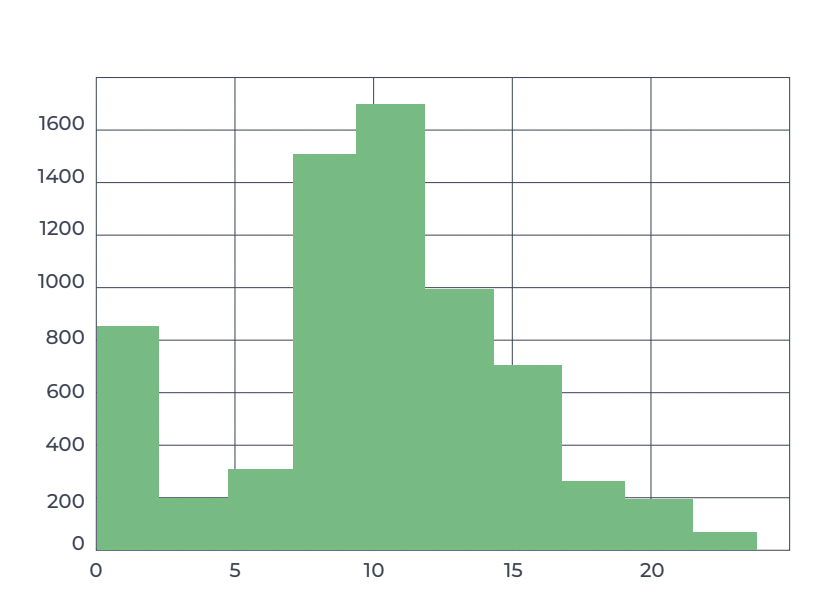
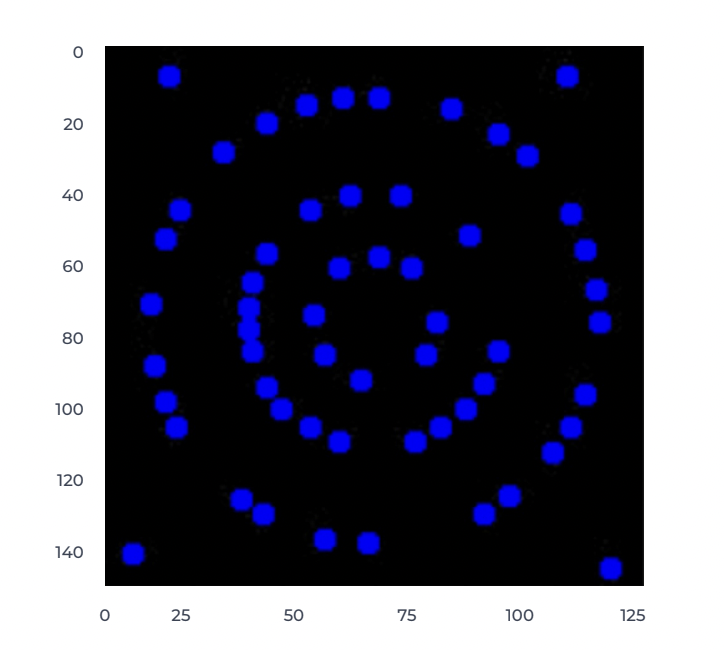
Multi-defect detection during manufacturing processes is a vital step to ensure product quality.
The timely detection of faults or defects and taking appropriate actions are essential to reduce operational and quality-related costs.
According to Aberdeen’s research, “Many organizations will have true quality-related costs as high as 15 to 20 percent of sales revenue.”
Despite the importance, it’s challenging to do when you have unsupervised data. With manual inspection processes usually being long and costly, it is clear why manufacturers are looking to leverage new technologies such as AI/ML to automate these tasks.
In this study, we show why it’s necessary to develop and implement smart algorithms to detect the anomalies and defects, even when the training data is not ideal.